That’s exactly the problem medical cannabis startup Montu set out to solve. As its patient base grew rapidly, Montu needed a way to scale without turning clinical conversations into rushed, impersonal calls. The answer came from a thoughtful combination of AI, cloud infrastructure, and Amazon Connect, all built on AWS.
Let’s break down how AI is quietly helping clinical staff have more human conversations and why this matters far beyond one fast growing healthcare company.
The Real Problem Isn’t Technology. It’s Cognitive Load.
Clinicians don’t struggle because they don’t care.
They struggle because they’re overloaded.
A typical clinical conversation today often looks like this:
- Reviewing patient history across multiple systems
- Confirming identity and compliance requirements
- Documenting notes in real time
- Navigating scheduling or follow-up steps
- Managing call queues or appointment backlogs
All of this happens while trying to listen, empathize, and respond thoughtfully.
What this really means is that the clinician’s attention is split. Not because they want it to be, but because the system demands it.
AI’s role here isn’t to speak for clinicians. It’s to remove friction so clinicians can focus on being present.
Why Human Conversations Matter More in Medical Cannabis
Medical cannabis sits at a unique intersection of healthcare.
Patients often come in with:
- Anxiety or chronic pain
- Previous negative healthcare experiences
- Confusion about legality, dosage, or side effects
- A need for reassurance, not judgment
These are not checkbox conversations. They require trust.
For Montu, scaling meant handling a rapidly growing number of patient interactions without losing the empathy that made the service work in the first place. That’s where AI powered contact center technology became a strategic decision, not just an operational one.
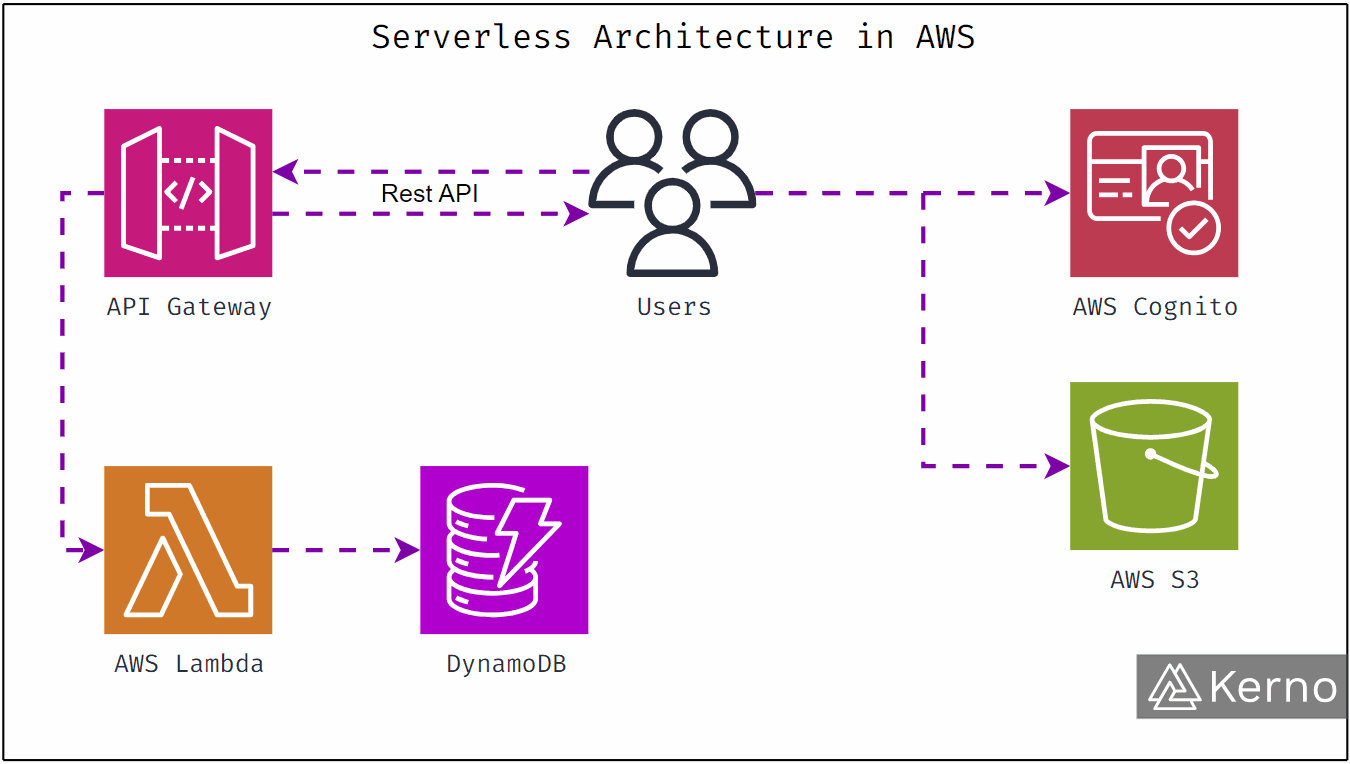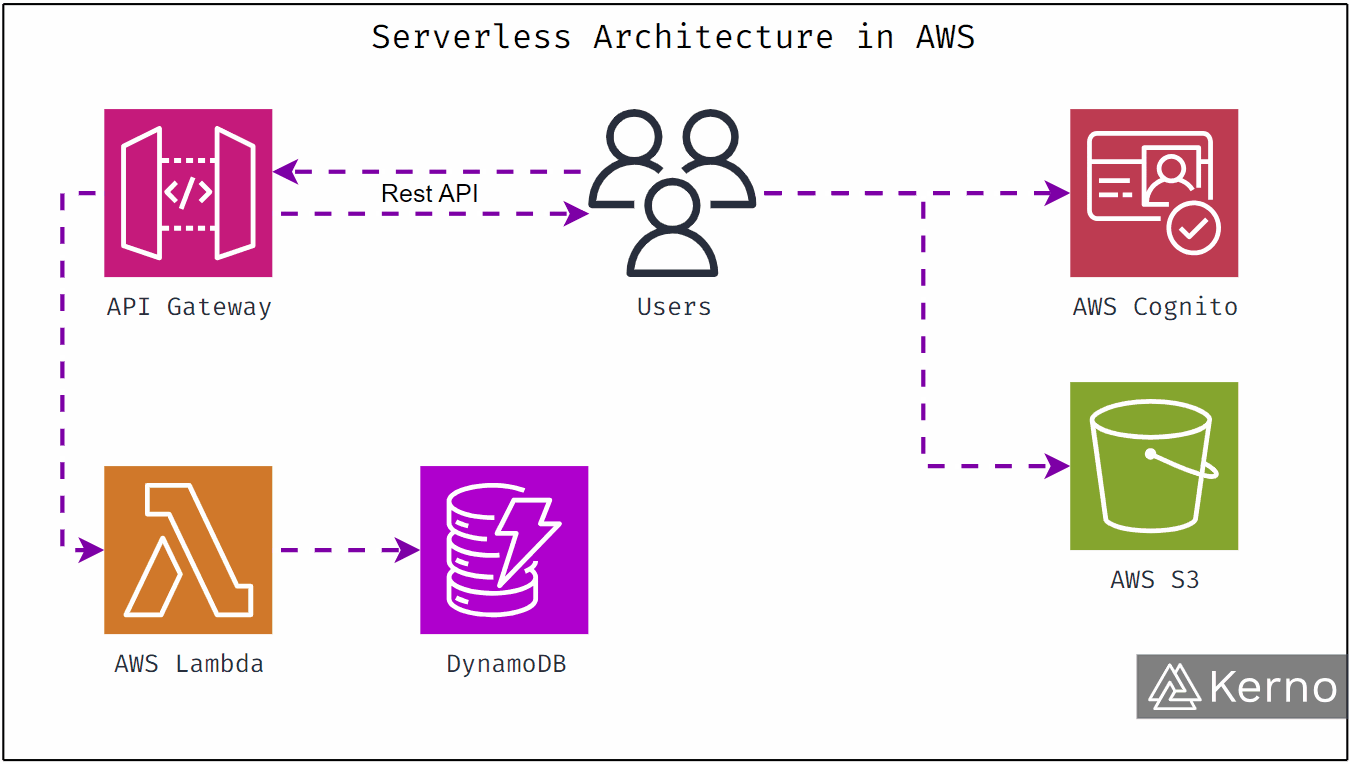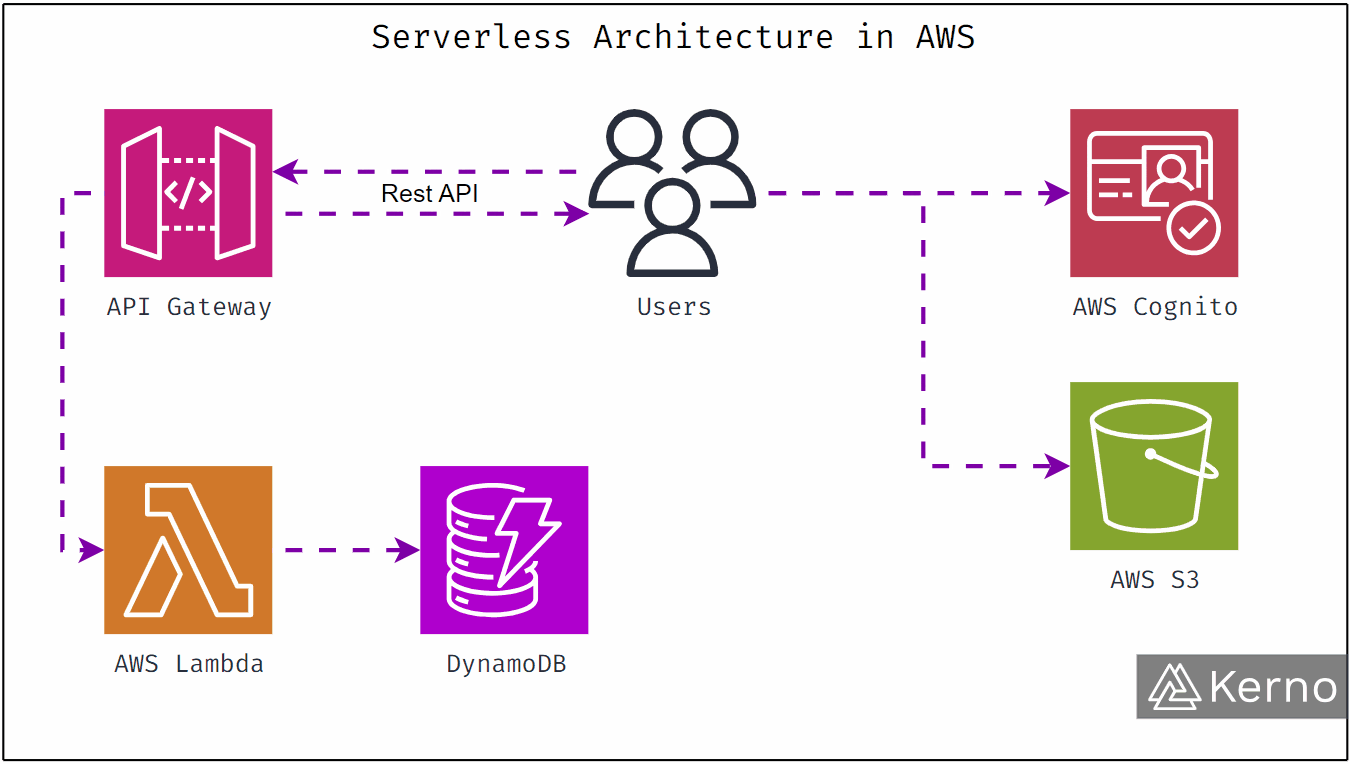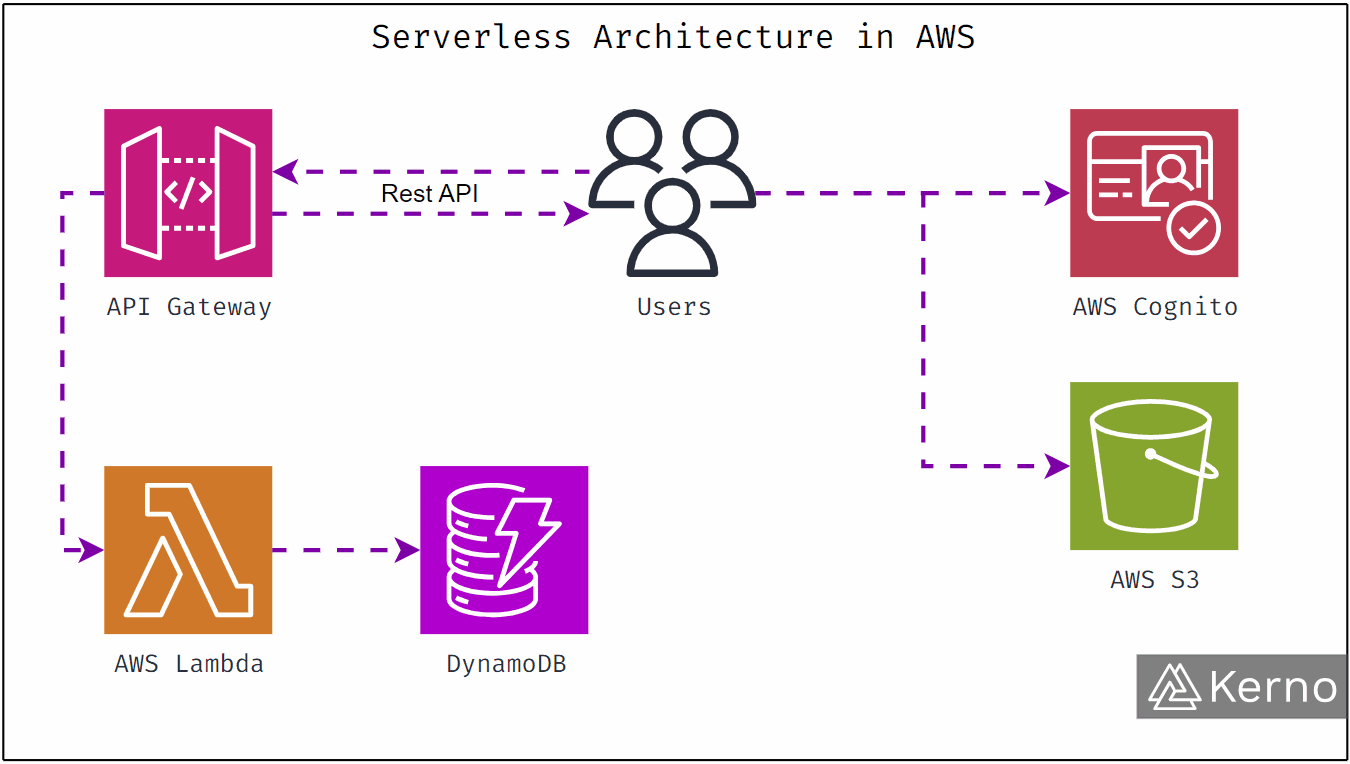
How Amazon Connect Changes the Shape of Clinical Conversations
At its core, Amazon Connect is a cloud based contact center designed to handle voice, chat, and messaging at scale. But its real power in healthcare comes from how it integrates with AI and data.
Here’s what changes when clinical teams use Amazon Connect.
One View of the Patient, Not Five Tabs
Instead of switching between systems, clinicians can see:
- Patient history
- Previous conversations
- Notes and outcomes
- Appointment context
All in one interface.
This reduces mental overhead. The clinician doesn’t start the call scrambling for context. They start informed, calm, and ready to listen.
Intelligent Call Routing That Respects People’s Time
AI driven routing ensures patients are connected to the right clinician based on:
- Medical needs
- Availability
- Previous interactions
This avoids repetitive explanations and long wait times. Patients feel seen. Clinicians feel prepared.


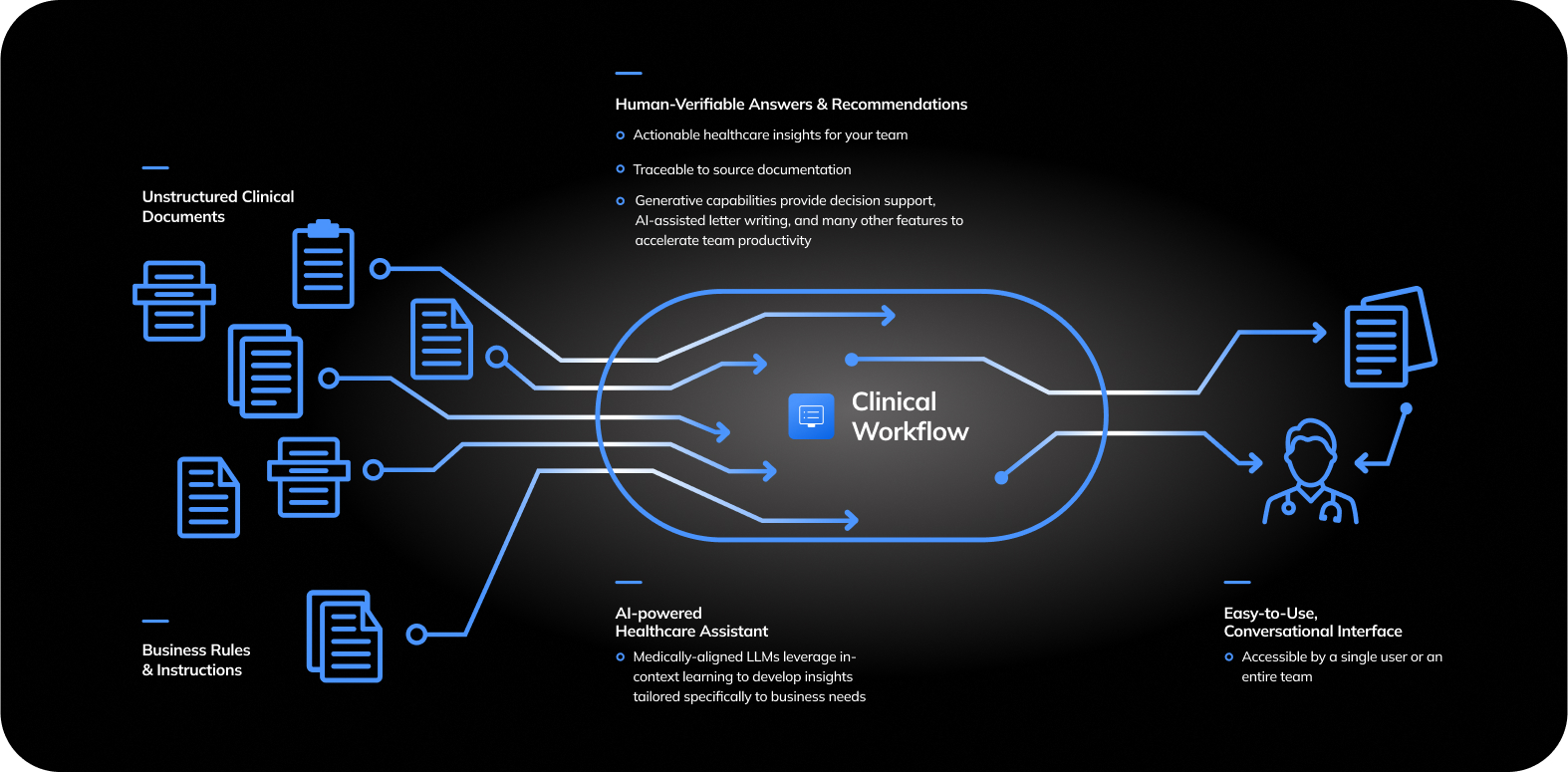
AI as a Silent Assistant, Not a Replacement
There’s a lot of noise around AI replacing jobs. In clinical care, that framing misses the point.
At Montu, AI plays a background role. It doesn’t diagnose. It doesn’t prescribe. It supports.
Here’s how.
Automated Transcription and Note Taking
AI can transcribe conversations in real time and structure notes automatically.
That means:
- Less typing during calls
- Better eye contact and listening
- More accurate records after the conversation ends
The clinician stays engaged. The documentation still gets done.
Smart Prompts, Not Scripts
AI can surface relevant prompts during a conversation:
- Follow-up questions
- Compliance reminders
- Patient specific considerations
These aren’t rigid scripts. They’re gentle nudges that help clinicians avoid missing important details while keeping the conversation natural.
Scaling Without Losing the Human Touch
Most startups hit a breaking point when growth outpaces systems.
Montu faced a classic challenge:
- More patients
- More clinicians
- More interactions
- The same expectation of care quality
Traditional scaling often leads to:
- Shorter calls
- More rigid processes
- Burned out staff
By building on AWS and Amazon Connect, Montu scaled infrastructure first, not pressure.
Elastic Infrastructure That Grows With Demand
Cloud based systems mean capacity adjusts automatically.
Busy periods don’t overwhelm clinicians. Quiet periods don’t waste resources. This balance keeps workloads sustainable, which directly impacts how clinicians show up in conversations.
Data Driven Insights Without Micromanagement
AI analytics help identify:
- Where patients drop off
- Which conversations take longer
- Where clinicians need support or training
This isn’t about surveillance. It’s about understanding patterns so teams can improve together.
The Emotional Impact on Clinical Staff
Here’s something that often gets overlooked.
When systems are better, clinicians feel better.
Reduced admin load leads to:
- Less fatigue
- More patience
- Better emotional regulation
And patients can feel the difference.
A clinician who isn’t rushing.
A pause that isn’t filled with keyboard noise.
A response that acknowledges emotion, not just symptoms.
AI doesn’t create empathy. It makes space for it.
Trust, Compliance, and Security on AWS
Healthcare conversations carry sensitive information. For Montu, trust wasn’t negotiable.
AWS provides:
- Enterprise grade security
- Compliance frameworks aligned with healthcare standards
- Encrypted data at rest and in transit
This allows clinical teams to focus on care, not fear of breaches or system failures.
Patients don’t see the infrastructure. They feel the confidence it creates.
What This Means for the Future of Healthcare Conversations
Montu’s experience highlights a broader shift happening across healthcare.
The next generation of clinical tools won’t be judged by how advanced they are. They’ll be judged by how invisible they become.
The best AI in healthcare:
- Reduces friction
- Amplifies listening
- Supports human judgment
- Disappears into the background
As healthcare systems grow more complex, the role of AI is to simplify the human experience on both sides of the conversation.
Key Takeaways for Healthcare Leaders
If you’re thinking about AI in healthcare, here’s what matters.
- Start with the conversation, not the technology
- Use AI to remove cognitive load, not replace empathy
- Choose platforms that scale without rigidity
- Measure success by patient trust and staff wellbeing
Montu’s approach shows that growth and humanity don’t have to be trade-offs.
With the right use of AI and AWS powered tools like Amazon Connect, they can reinforce each other.
Final Thought
Here’s the thing.
Patients don’t remember how advanced your systems are.
They remember how the conversation made them feel.
AI, when used thoughtfully, doesn’t make healthcare colder.
It gives clinicians the space to be warmer.
And that might be its most important contribution of all.